|
Welcome! My name is Yunhai Han and I am a Robotics PhD student at Georgia Institute of Technology, advised under Prof. Harish Ravichandar. I am also fortunate to have worked with Prof. Sehoon Ha, Prof. Zsolt Kira, and Prof. Danfei Xu. My research focus at Gatech is about structured robot learning. I am also honoured to be an awardee of Robotics PhD fellowship from Georgia Tech's Institute for Robotics and Intelligent Machines (IRIM). Before coming to Georgia Tech, I received my M.S. / B.S. in Mechanical Engineering from UCSD, 2021 and Yanshan University, 2019, respectively. I'm open to discussions and collaborations, so feel free to drop me an email if you are interested. Email / CV(Aug 2025) / Github / Google Scholar / Linkdin |

|
|
I have a broad interest in robotics, especially robot learning for manipulation tasks under complex environments, i.e., at home. I enjoy developing algorithms for robotic applications and I would like to explore how robots could learn and perceive the world to achieve high-level automation skills in dynamical environments. My love to robotics stems from a famous Japanese anime series: Code Geass(コードギアス 反逆のルルーシュ). I was dreaming of building a macha when I was a high school student. |
|
|
|
Kelin Yu (CS M.S., 2022-2024, now PhD at UMD CS) |
|
Jeonghwan Kim (GT CS PhD in Prof. Sehoon Ha's lab) |
|
|
|
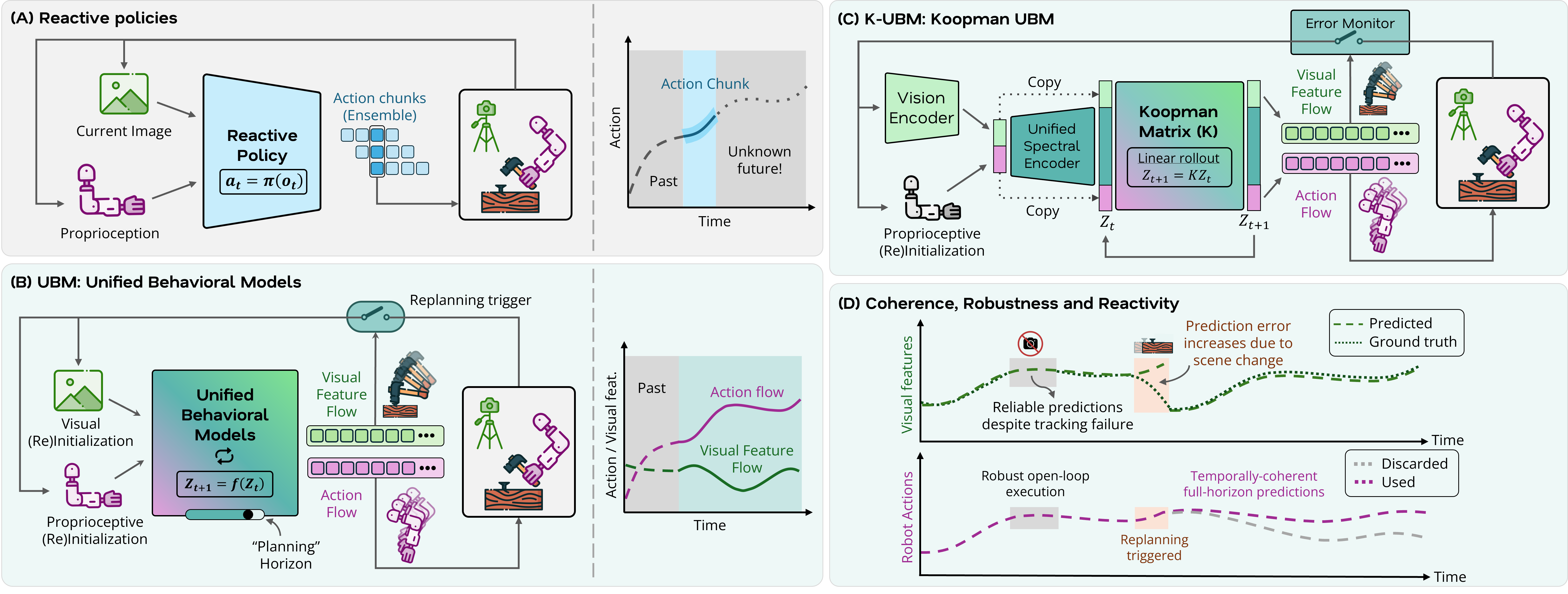
Yunhai Han, Linhao Bai*, Ziyu Xiao*, Zhaodong Yang*, Yogita Choudhary, Krishna Jha, Chuizheng Kong, Shreyas Kousik, Harish Ravichandar (* Equal contribution) Under review There has been rapid and dramatic progress in robots' ability to learn complex visuo-motor manipulation skills from demonstrations, thanks in part to expressive policy classes that employ diffusion- and transformer-based backbones. However, these design choices require significant data and computational resources and remain far from reliable, particularly within the context of multi-fingered dexterous manipulation. Fundamentally, they model skills as reactive mappings and rely on fixed-horizon action chunking to mitigate jitter, creating a rigid trade-off between temporal coherence and reactivity. In this work, we introduce Unified Behavioral Models (UBMs), a framework that learns to represent dexterous skills as coupled dynamical systems that capture how visual features of the environment (visual flow) and proprioceptive states of the robot (action flow) co-evolve. By capturing such behavioral dynamics, UBMs can ensure temporal coherence by construction rather than by heuristic averaging. To operationalize these models, we propose Koopman-UBM, a first instantiation of UBMs that leverages Koopman Operator theory to effectively learn a unified representation in which the joint flow of latent visual and proprioceptive features is governed by a structured linear system. We demonstrate that Koopman-UBM can be viewed as an implicit planner: given an initial condition, it analytically computes the desired robot behavior while simultaneously ``imagining" the resulting flow of visual features over the entire skill horizon. [arXiv] |
|
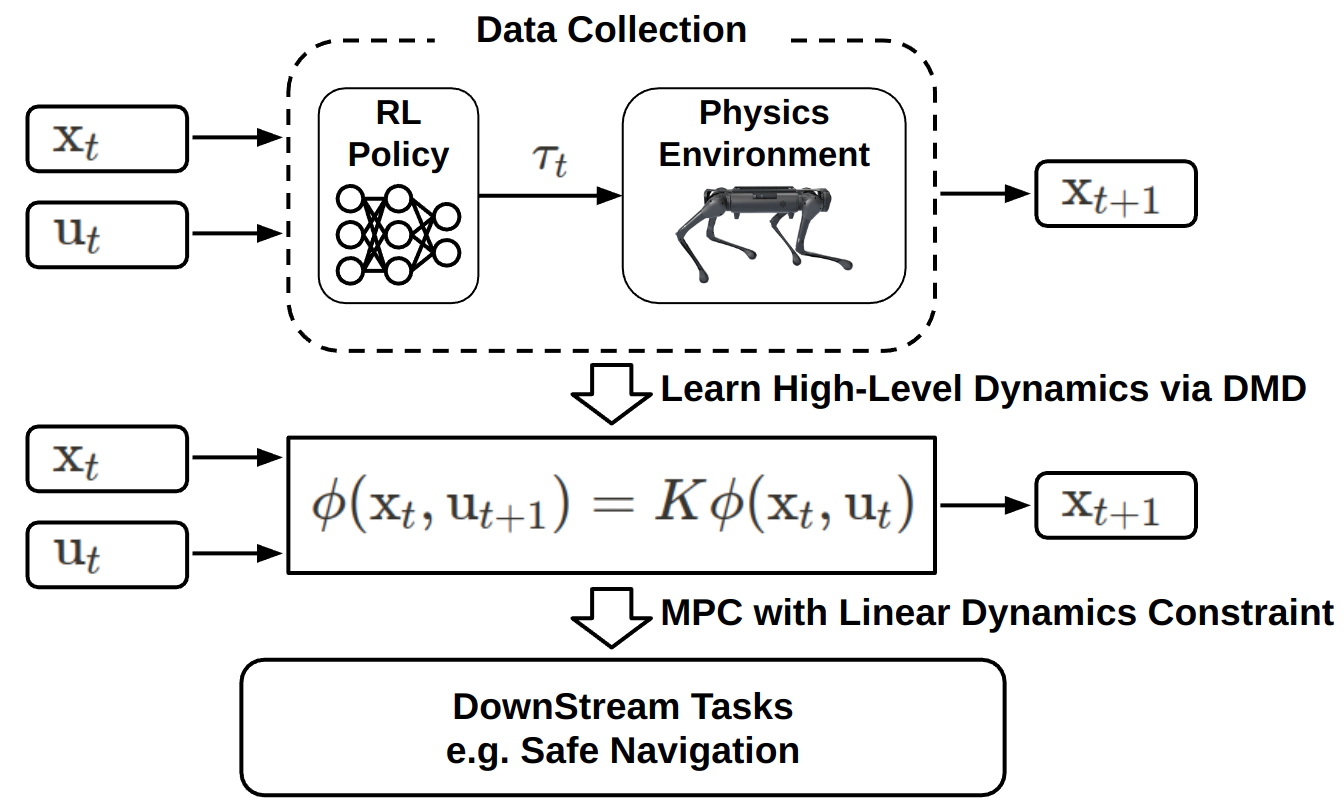
Jeonghwan Kim, Yunhai Han, Harish Ravichandar, Sehoon Ha Under review Nonlinearity in dynamics has long been a major challenge in robotics, often causing significant performance degradation in existing control algorithms. For example, the navigation of bipedal robots can exhibit nonlinear behaviors even under simple velocity commands, as their actual dynamics are governed by complex whole-body movements and discrete contacts. In this work, we propose a novel safe navigation framework inspired by Koopman operator theory. We first train a low-level locomotion policy using deep reinforcement learning, and then capture its low-frequency, base-level dynamics by learning linearized dynamics in a high-dimensional lifted space using Dynamic Mode Decomposition. Then, our model-predictive controller (MPC) efficiently optimizes control signals via standard quadratic objective and the linear dynamics constraint in the lifted space. We demonstrate that the Koopman-based model more accurately predicts bipedal robot trajectories than baseline approaches. Furthermore, we show that the proposed navigation framework achieves improved safety with better success rates in dense environments with narrow passages. [arXiv][Webpage] |

|
Yangcen Liu*, Woochul Shin*, Yunhai Han, Zhenyang Chen, Harish Ravichandar, Danfei Xu (* Equal contribution) Accepted by CoRL 2025 (Oral) & Spotlight at RSS Dex Workshop Learning robot manipulation from abundant human videos offers a scalable alternative to costly robot-specific data collection. However, domain gaps across visual, morphological, and physical aspects hinder direct imitation. To effectively bridge the domain gap, we propose ImMimic, an embodiment-agnostic co-training framework that leverages both human videos and a small amount of teleoperated robot demonstrations. ImMimic uses Dynamic Time Warping (DTW) with either action- or visual-based mapping to map retargeted human hand poses to robot joints, followed by MixUp interpolation between paired human and robot trajectories. Our key insights are (1) retargeted human hand trajectories provide informative action labels, and (2) interpolation over the mapped data creates intermediate domains that facilitate smooth domain adaptation during co-training. Evaluations on four real-world manipulation tasks (Pick and Place, Push, Hammer, Flip) across four robotic embodiments (Robotiq, Fin Ray, Allegro, Ability) show that ImMimic improves task success rates and execution smoothness, highlighting its efficacy to bridge the domain gap for robust robot manipulation. [Arxiv][Webpage] |

|
Hanyao Guo*, Yunhai Han*, Harish Ravichandar (* Equal contribution; Guo is my master student advisee) Under review When learning stable linear dynamical systems from data, three important properties are desirable: i) predictive accuracy, ii) verifiable stability, and iii) computational efficiency. Unconstrained minimization of prediction errors leads to high accuracy and efficiency but cannot guarantee stability. Existing methods to enforce stability often preserve accuracy, but do so only at the cost of increased computation. In this work, we investigate if a seemingly-naive procedure can simultaneously offer all three desiderata. Specifically, we consider a post-hoc procedure in which we surgically manipulate the spectrum of the linear system after it was learned using unconstrained least squares. We call this approach spectral clipping (SC) as it involves eigen decomposition and subsequent reconstruction of the system matrix after any eigenvalues whose magnitude exceeds one have been clipped to one (without altering the eigenvectors). We also show that SC can be readily combined with Koopman operators to learn nonlinear dynamical systems that can generate stable predictions of nonlinear phenomena, such as those underlying complex dexterous manipulation skills involving multi-fingered robotic hands. Through comprehensive experiments involving two different applications and publicly available benchmark datasets, we show that this simple technique can efficiently learn highly-accurate predictive dynamics that are provably-stable. Notably, we find that SC can match or outperform strong baselines while being orders-of-magnitude faster. Finally, we find that SC can learn stable robot policies even when the training data includes unsuccessful or truncated demonstrations. [Arxiv][Code] |
|
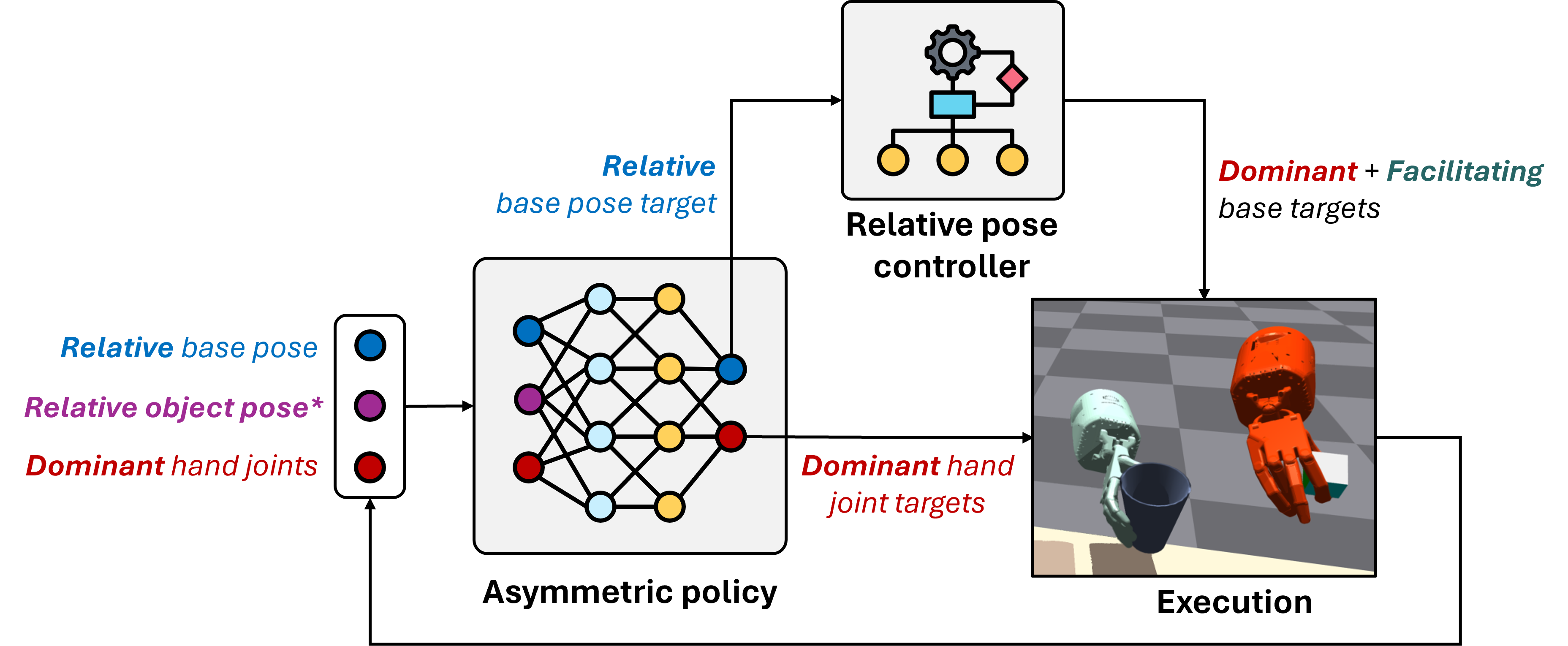
Zhaodong Yang, Yunhai Han, Harish Ravichandar Spotlight at RSS Whole-body Control and Bimanual Manipulation Workshop, 2025, Poster at CoRL Whole-body Control and Bimanual Manipulation Workshop, 2024 We present Asymmetric Dexterity (AsymDex), a novel reinforcement learning (RL) framework that can efficiently learn asymmetric bimanual skills for multi-fingered hands without relying on demonstrations, which can be cumbersome to collect. Two crucial ingredients enable AsymDex to reduce the observation and action space dimensions and improve sample efficiency. First, AsymDex leverages the natural asymmetry found in human bimanual manipulation and assigns specific and interdependent roles to each hand: a facilitating hand that moves and reorients the object, and a dominant hand that performs complex manipulations on said object. Second, AsymDex defines and operates over relative observation and action spaces, facilitating responsive coordination between the two hands. Further, AsymDex can be easily integrated with recent advances in grasp learning to handle both the object acquisition phase and the interaction phase of bimanual dexterity. Unlike existing RL-based methods for bimanual dexterity, which are tailored to a specific task, AsymDex can be used to learn a wide variety of bimanual tasks that exhibit asymmetry. Detailed experiments on four simulated asymmetric bimanual dexterous manipulation tasks reveal that AsymDex consistently outperforms strong baselines that challenge its design choices, in terms of success rate and sample efficiency. [OpenReview][Webpage] |
|
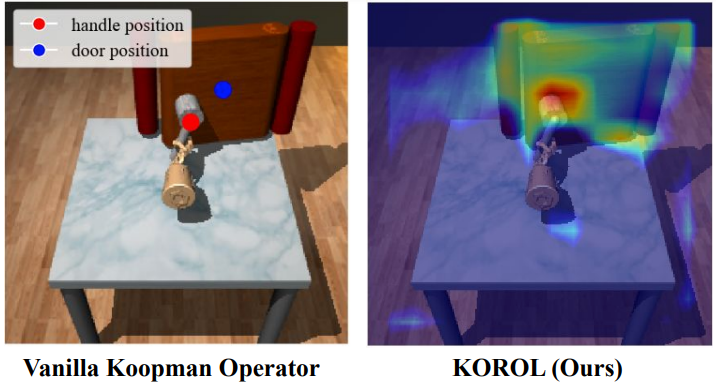
Hongyi Chen, Abulikemu Abuduweili*, Aviral Agrawal*, Yunhai Han*, Harish Ravichandar, Changliu Liu, and Jeffrey Ichnowski (* Equal contribution) Accepted by CoRL 2024 Learning dexterous manipulation skills presents significant challenges due to complex nonlinear dynamics that underlie the interactions between objects and multi-fingered hands. Koopman operators have emerged as a robust method for modeling such nonlinear dynamics within a linear framework. However, current methods rely on runtime access to ground-truth (GT) object states, making them unsuitable for vision-based practical applications. Unlike image-to-action policies that implicitly learn visual features for control, we use a dynamics model, specifically the Koopman operator, to learn visually interpretable object features critical for robotic manipulation within a scene. We construct a Koopman operator using object features predicted by a feature extractor and utilize it to auto-regressively advance system states. We train the feature extractor to embed scene information into object features, thereby enabling the accurate propagation of robot trajectories. We evaluate our approach on simulated and real-world robot tasks, with results showing that it outperformed the model-based imitation learning NDP by 1.08× and the image-to-action Diffusion Policy by 1.16×. [arXiv][OpenReview][Code] |
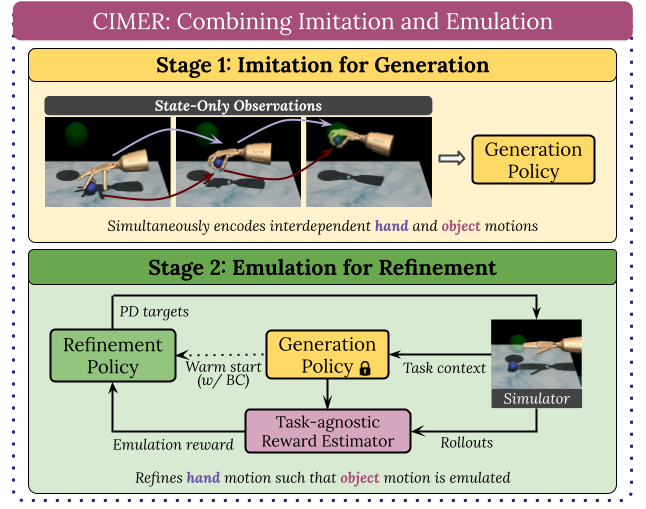
|
Yunhai Han, Zhenyang Chen, Kyle A Williams, and Harish Ravichandar Accepted by RA-L When human acquire physical skills (e.g., tennis) from experts, we tend to first learn from merely observing the expert. But this is often insufficient. We then engage in practice, where we try to emulate the expert and ensure that our actions produce similar effects on our environment. Inspired by this observation, we introduce Combining IMitation and Emulation for Motion Refinement (CIMER) -- a two-stage framework to learn dexterous prehensile manipulation skills from state-only observations. CIMER's first stage involves imitation: simultaneously encode the complex interdependent motions of the robot hand and the object in a structured dynamical system. This results in a reactive motion generation policy that provides a reasonable motion prior, but lacks the ability to reason about contact effects due to the lack of action labels. The second stage involves emulation: learn a motion refinement policy via reinforcement that adjusts the robot hand's motion prior such that the desired object motion is reenacted. CIMER is both task-agnostic (no task-specific reward design or shaping) and intervention-free (no additional teleoperated or labeled demonstrations). [arXiv][Webpage][Code] |
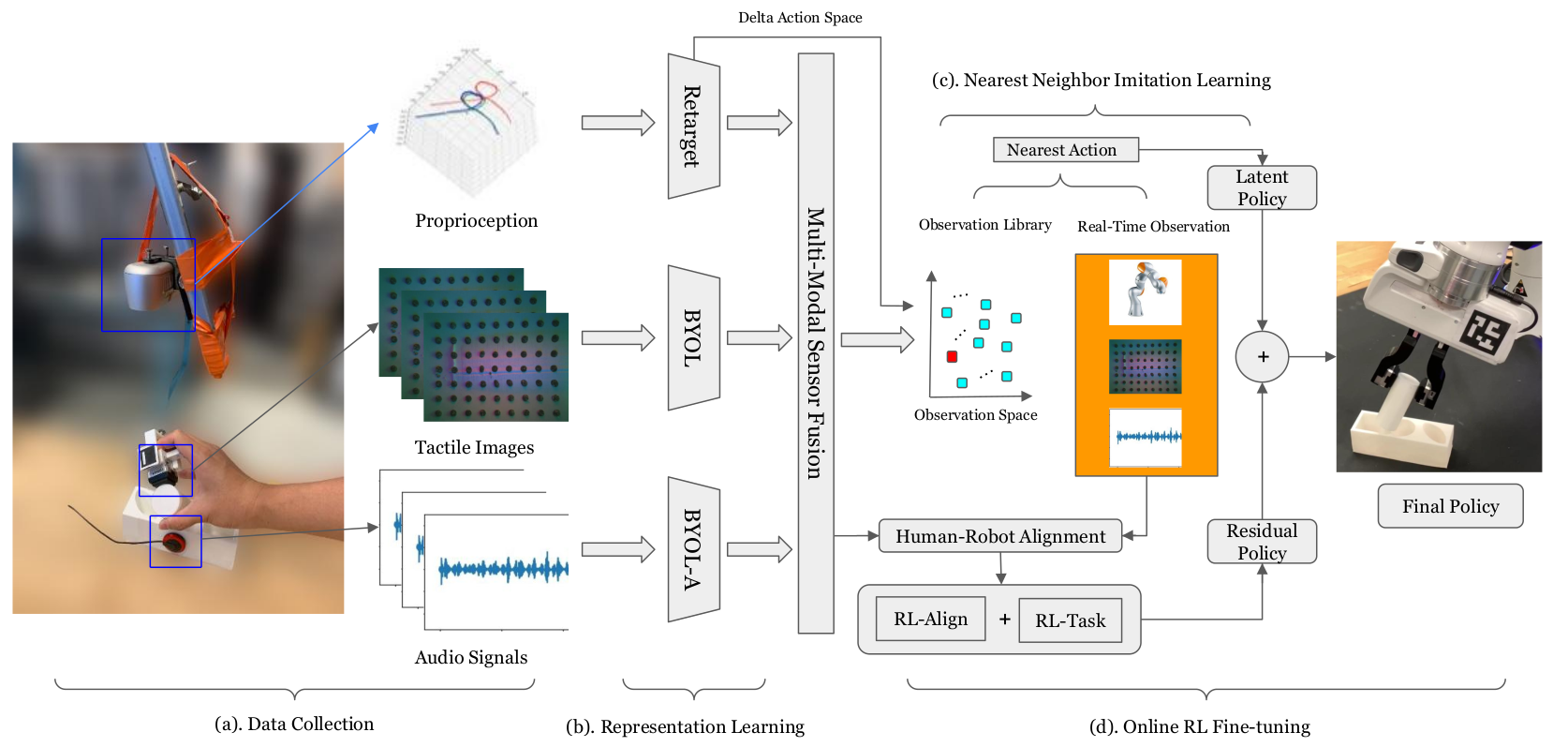
|
Kelin Yu*, Yunhai Han*, Qixian Wang, Vaibhav Saxena, Danfei Xu, and Ye Zhao (* Equal contribution; Yu is my master student advisee) Accepted by CoRL 2024 & Best Paper at NeurIPS Touch Processing Workshop & Poster at CoRL Deployable Workshop, 2023 Tactile sensing is critical to fine-grained, contact-rich manipulation tasks, such as insertion and assembly. An effective strategy to learn tactile-guided policy is to train neural networks that map tactile signal to control based on teleoperated demonstration data. However, to provide the teleoperated demonstration, human users often rely on visual feedback to control the robot. This creates a gap between the sensing modality used for controlling the robot (visual) and the modality of interest (tactile). To bridge this gap, we introduce MimicTouch, a novel framework for learning policies directly from demonstrations provided by human users with their hands. The key innovations are i) a human tactile data collection system which collects multi-modal tactile dataset for learning human's tactile-guided control strategy, ii) an imitation learning-based framework for learning human's tactile-guided control strategy through such data, and iii) an online residual RL framework to bridge the embodiment gap between the human hand and the robot gripper. [arXiv][OpenReview][Webpage] |
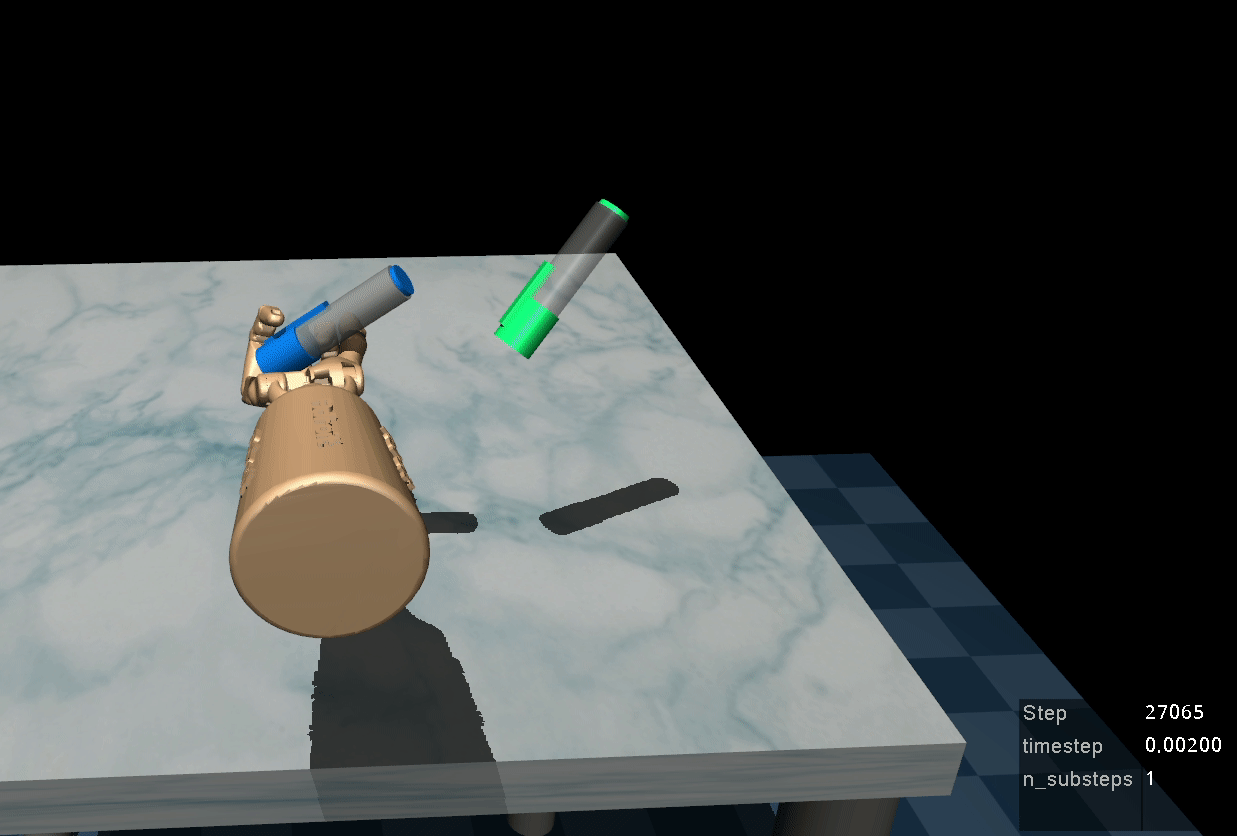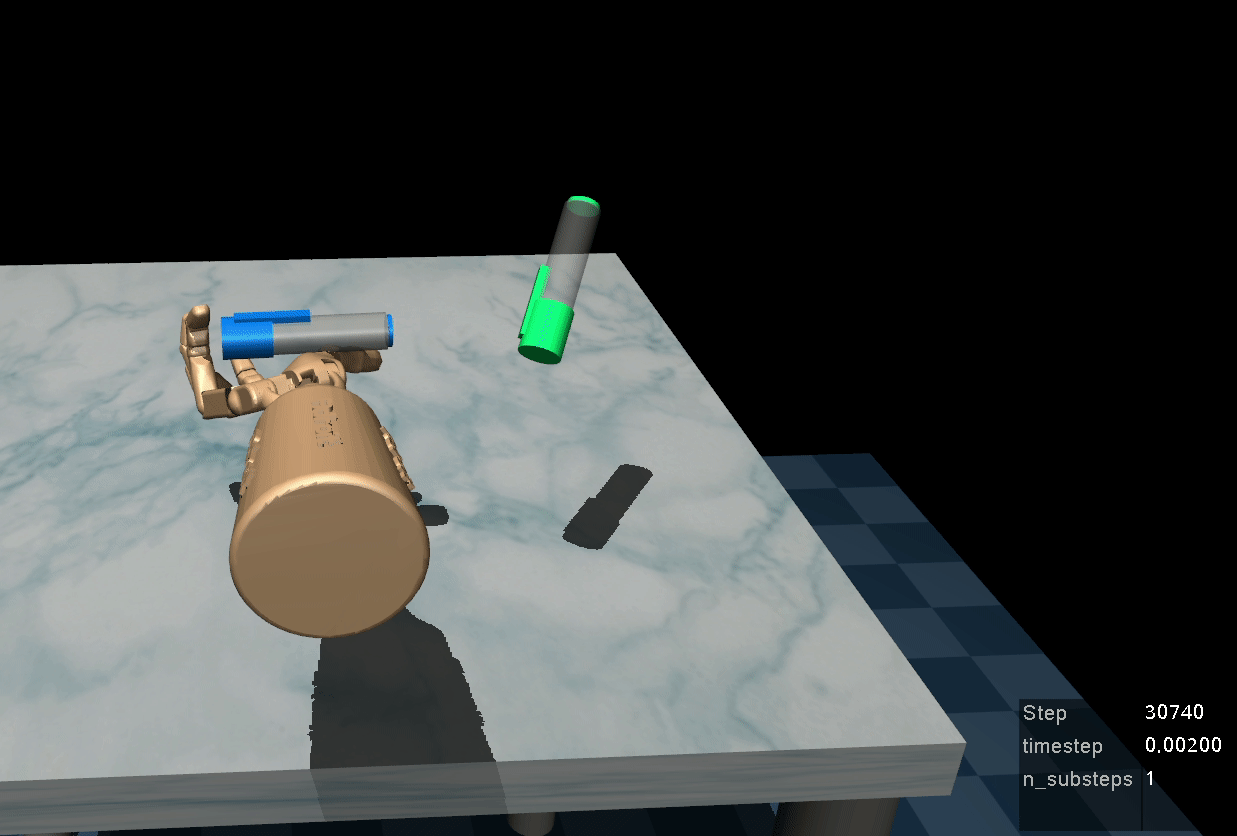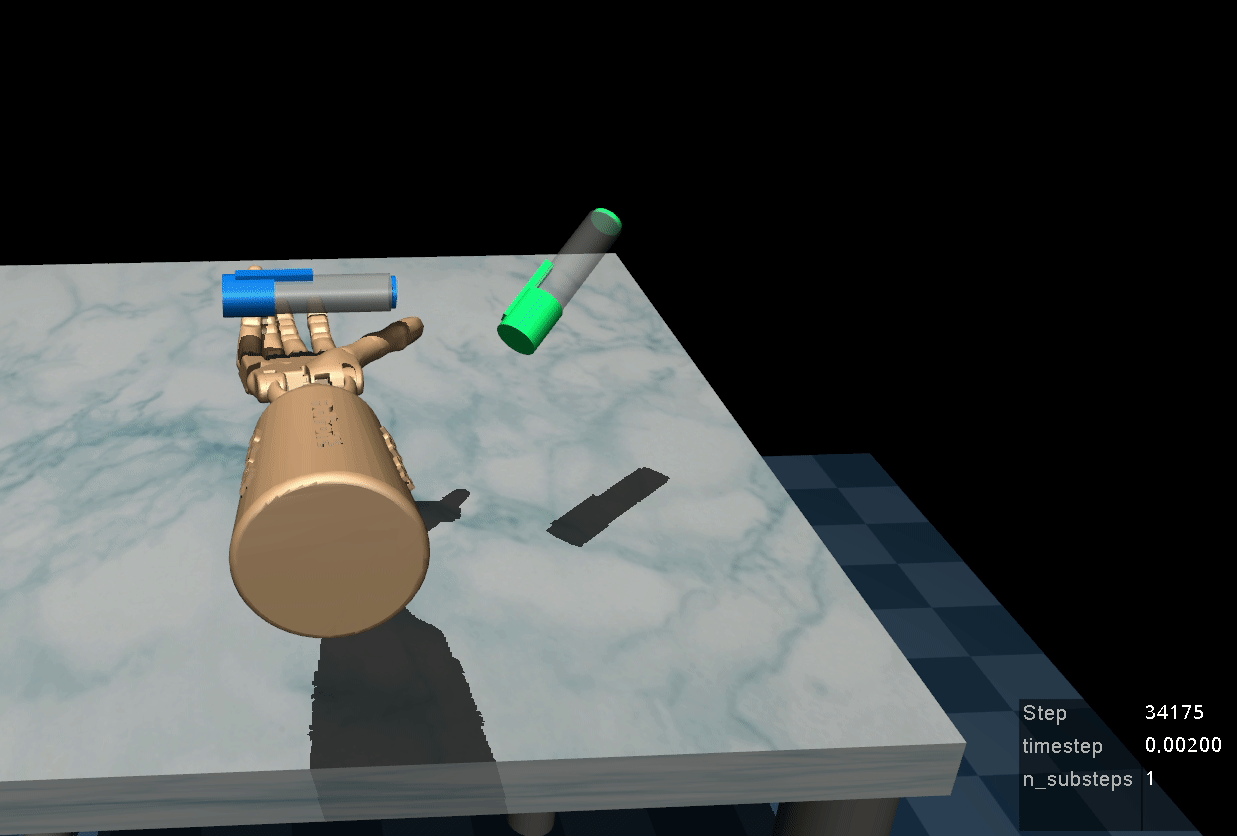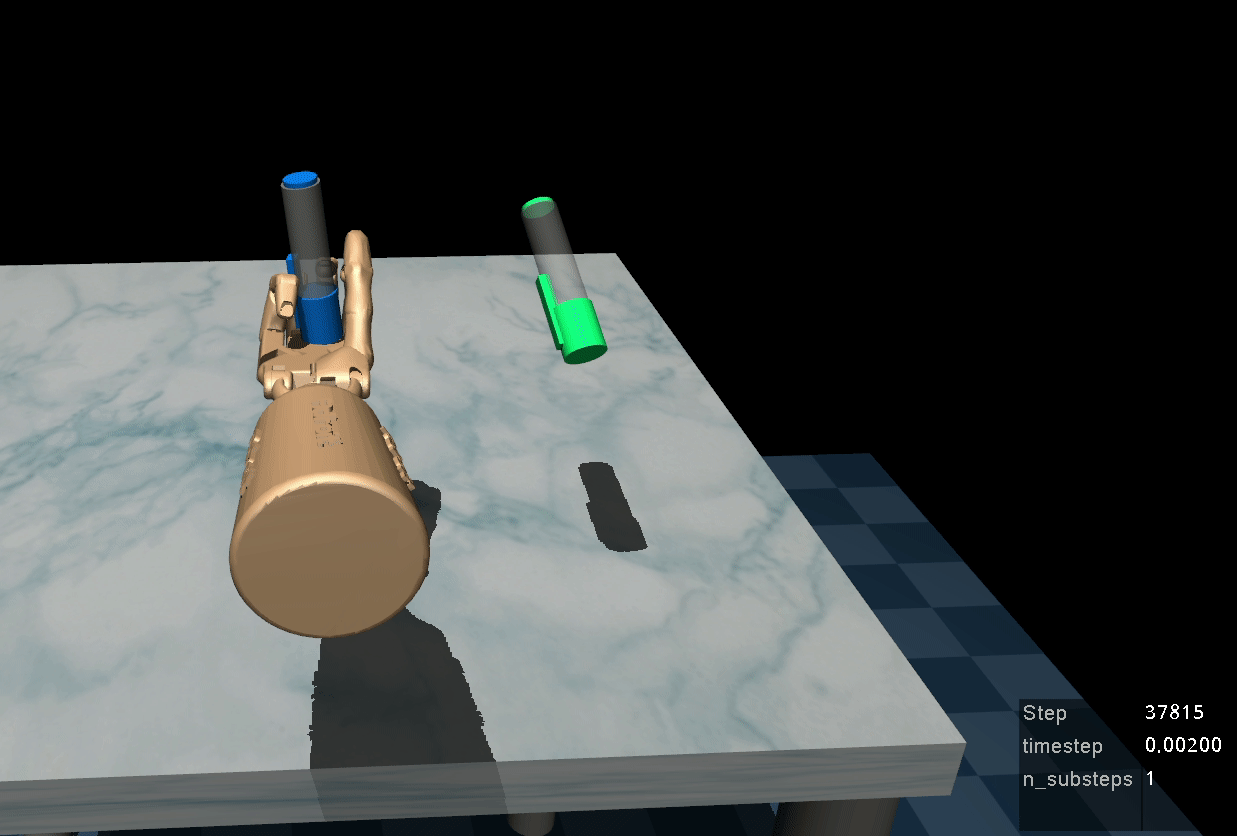
|
Yunhai Han, Mandy Xie, Ye Zhao, and Harish Ravichandar Accepted by CoRL 2023 (Oral) This work enables to learn dexterous manipulation skills from a few pieces of demonstration data. Dexterous manipulation is known to be very complex due to the absence of well-studied analytical models and high DoFs. Most existing work addresses this challenge via training a Reinforcement learning (RL) agent with fine-tuned shaped rewards. Motivated by the fact that complex nonlinear dynamics underlie dexterous manipulation and Koopman operators are simple yet powerful control-theoretic structures that help represent complex nonlinear dynamics as linear systems in higher-dimensional spaces, we propose a Koopman operator-based framework (KODex) and demonstrate that it is surprisingly effective for learning dexterous manipulation tasks and offers a number of unique benefits. [arXiv][OpenReview][Webpage][Code] |

|
Michael E. Cao⋆, Jonas Warnke⋆, Yunhai Han, Xinpei Ni, Ye Zhao, and Samuel Coogan (* Equal contributions) Accepted by SSRR, 2022 This work introduces a high-level controller synthesis framework that enables teams of heterogeneous agents to assist each other in resolving environmental conflicts that appear at runtime. This conflict resolution method is built upon temporal-logic-based reactive synthesis to guarantee safety and task completion under specific environment assumptions. Additionally, we implement the proposed framework on a physical multi-agent robotic system to demonstrate its viability for real world applications. [arXiv][Video] |
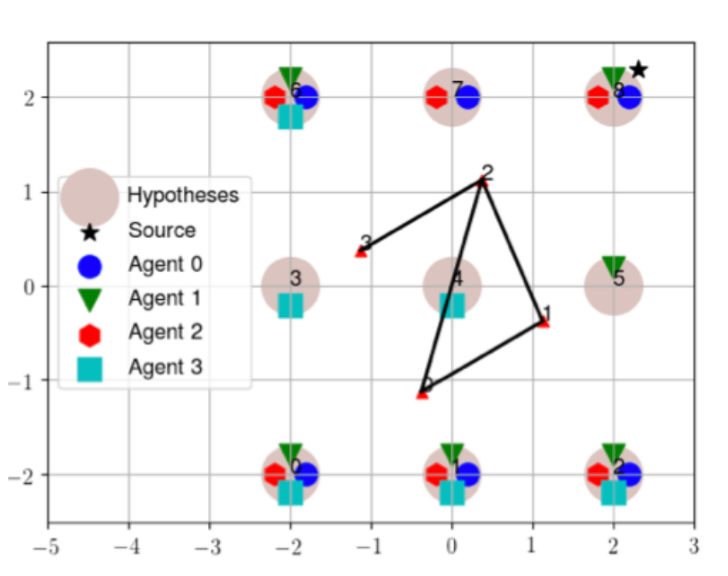
|
Yunhai Han and Sonia Martínez Accepted by L-CSS and ACC, 2022 This work proposes a numerical method to verify differential privacy in estimation with performance guarantees. To achieve differential privacy, a mechanism (estimator) is turned into a stochastic mapping; which makes it hard to distinguish outputs produced by close inputs. While obtaining theoretical conditions that guarantee privacy may be possible, verifying these in practice can be hard. [arXiv][slides] |
|
Henrik Christensen, David Paz, Hengyuan Zhang, Dominique Meyer, Hao Xiang, Yunhai Han, Yuhan Liu, Andrew Liang, Zheng Zhong, Shiqi Tang Accepted by Autonomous Intelligent System, Springer, 2021 My teammates at AVL lab and I warpped up the technical details when we explored and developed robust autonomous car systems and architectures for mail-delivery and micro-transit applications on UCSD campus. In this paper, we first tell the details of the initial design experiments and the main lessons/short-comings from the deployments. Then, we present the various approaches to address these challenges. Finally, we outline our future work. My work for this journal paper mainly involves the auto-calibration system for urban autonomous driving. [Springer] |

|
Yunhai Han*, Kelin Yu*, Rahul Batra, Nathan Boyd, Chaitanya Mehta, Tuo Zhao, Yu She, Seth Hutchinson, and Ye Zhao Accepted by T-MECH Reliable robotic grasping with deformable objects remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics, and variable object geometries. In this study, we propose a Transformer-based robot grasping framework for rigid grippers that leverage tactile information from a GelSight sensor for safe object grasping. The Transformer network learns physical feature embeddings from visual & tactile feedback and predict a final grasp through a multilayer perceptron (MLP) with grasping strength. Using these predictions, the gripper is commanded with an optimal force for safe grasping tasks. [arXiv] [Webpage] [Video] |
|
Yunhai Han, Fei Liu and Michael C. Yip Spotlight presentation at IROS Workshop, 2020 This framework continuously tracks the motion of manipulator and simulates the tissue deformation in presence of collision detection. The deformation energy can be computed for the control and planning task. [arXiv] [slides][Talk] |

|
Yunhai Han*, Yuhan Liu*, David, paz and Henrik Christensen (* Equal contributions) Accepted by ICRA, 2021 For use of cameras on an intelligent vehicle,driving over a major bump could challenge the calibration. It isthen of interest to do dynamic calibration. What structures canbe used for calibration? How about using traffic signs that yourecognize? In this paper an approach is presented for dynamic camera calibration based on recognition of stop signs. [arXiv] [Dataset] |
|
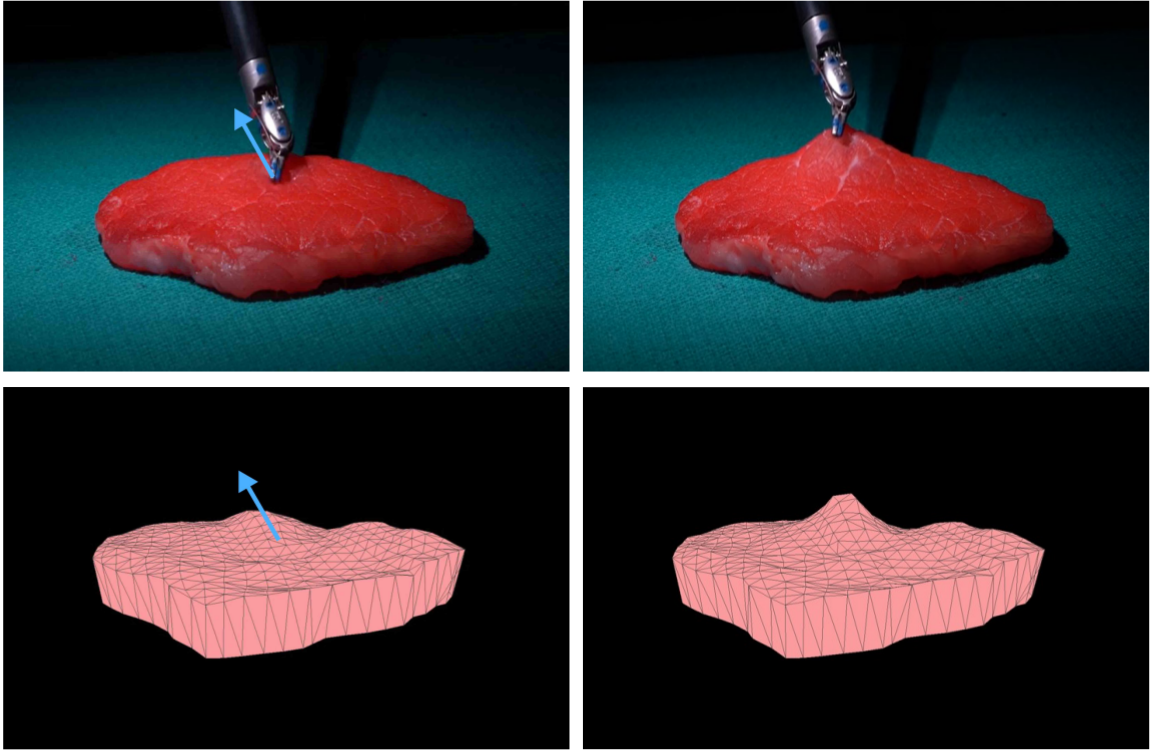
Fei Liu*, Zihan Li*, Yunhai Han, Jingpei Lu, Florian Richter and Michael C. Yip (* Equal contributions) Accepted by ICRA, 2021 Autonomy in robotic surgery is very challenging in unstructured environments, especially when interacting with soft tissues. In this work, we propose an online, continuous, registration method to bridge from 3D visual perception to position-based dynamics modeling of tissues. [arXiv][Video] |
|
|

|
RoboMaster The RoboMaster program is a platform for robotic competitions and academic exchange founded by Da-Jiang Innovations (DJI). Each team has to design and build a squad of multiple-purpose robots for skirmish combats. I was the vision group leader of YSU Eagle. My group were mainly responsible for the system design of visual components (including object tracking, range estimation and serial port communication) and the PID stability adjustment of the gimbal unit on the mobile tank (to prevent bumps and collisions during movement). [RoboMaster Overview][Our robots] |
|
GT RoboGrads
ICRA-2021
AIM-2021
ICRA-2022
IROS-2022
ACC-2022
SSRR-2022
ICRA-2023 |
|
MAE145, Robotic Planning & Estimation, UCSD
MAE146, Introduction to ML Algorithms, UCSD |
|
Research Assistant, Georgia Institute of Technology |
|
Running: Once finished half-marathon (21km) within 2 hours |
|
|